Bangla-Ring
Minimal Glyph Set FAQ:
-
What is a Minimal Glyph Set?
-
What does ISO 8859 compliance mean?
-
Why do we need an MGS?
-
What is a Standard Glyph Set?
-
Why do we need the SGS?
-
Who make the MGS and the SGS?
-
How does all this fit into Unicode?
-
Is this compatible with ISCII?
-
Do you have a set of proposed rules to
define the MGS?
-
Which softwares support MGS?
-
How do I make a suggestion for the MGS/SGS?
Answers:
-
What is a Minimal Glyph Set?
The Minimal Glyph Set for Bangla is
an 8 bit font map for Bangla which is in a certain sense "minimally sufficient"
but may not be "complete". The character map in the MGS is completely defined
and can not be changed. This immutable and sufficient character set can
be used to display all used characters of contemporary Bangla texts. However,
the character set has empty spaces for private use in it that can be utilized
for new characters. These redundant spaces can also be used to redefine
a ligature for improved appearance. The MGS is also ISO 8859 compliant.
-
What does ISO 8859 compliance mean?
ISO 8859-1 is the character set commonly
known as Latin 1. It can represent most Western European Languages. The
original version of HTML supported only ISO 8859-1. Since then it has expanded
its scope to include other character sets. ISO compliance for the MGS primarily
means that it does not house glyphs in positions 0-31 and 128-159 of the
font character set. These character ranges are reserved for control characters.
By not using these spaces, the MGS becomes usable for all Web applications
and Java.
-
Why do we need an MGS?
Currently there is no standard Glyph
Set or Character Set that can serve as a standard 8 bit font for Bangla
(or any Indic language for that matter). The available 8 bit fonts all
differ from one another in the sequence and position of characters. They
even differ in the actual repertoir of ligatures used in the font. Chaotic
font development has led to two problems:
-
Absense of a standard font map. Fonts
usable in one application are therefore un-usable in another one.
-
Because the range of applicability of
any font is limited, there is no incentive for making well-kerned and well-hinted
fonts for computer.
If the MGS is adopted as a standard then
the above problems can be tackled and a new generation of fine fonts will
appear which can be used by all applications.
-
What is a Standard Glyph Set?
The Standard Glyph Set for Bangla
is a "complete" and "sufficient" font map that is likely to appear by concensus,
once the MGS is in use for a while. The SGS will "embed" the MGS, but may
use some or all of the private area spaces of the MGS to expand the sope
of the font. There may even be several SGS's, named according to some naming
convention which will differ from each other in the way the private area
spaces are used.
-
Why do we need the SGS?
The SGS will be the first step toward
standardizing the 8 bit Bangla font. The SGS will inherit the benefits
of the MGS. In addition it will be more versatile, possibly with specific
standards targetted at specific uses of the language.
-
Who make the MGS and the SGS?
All standards must be evolved by users
of the languages. The MGS and SGS will be developed by Bangla font users
from all over the world. Parabaas proposes the Bangla Ring an open,
public consortium to facilitate this process.
-
How does all this fit into Unicode?
Unicode is a standard for character
maps. For Indic languages, the font map standards as described above (MGS
and SGS) have simply not emerged yet. The character maps that have been
standardized comprise of only elementary characters. Unicode fixes the
position of the letter "ka" for instance but says nothing about where to
put the glyph for the compound character "kta" in a Unicode font. Any text
can be coded in Unicode by expressing compound characters in terms of elemntary
ones. Simple rules can be formed (for instance by using "hasant" as a control
character) so that the actual Bangla text can be retrieved from the Unicode
encoding. However, Unicode does not dictate how the text is to be displayed
in terms of glyphs. In practice, a Unicode font for Bangla must use the
private use area of the font to house many compound glyphs. Indeed there
is not enough space in the area ear-marked for Bangla to house all of them.
However, there is no standard character map for the compound glyphs one
needs to house in the private use area. The MGS and the SGS may help us
to make a standard Unicode-MGS and Unicode-SGS for Bangla one day.
-
Is this compatible with ISCII?
ISCII is the equivalent of ASCII for
Indic languages as far as text encoding is concerned. It is also just a
character map standard for the elementary characters in languages where
the character set has a large intersection with the character set of the
Brahmi script. In fact the Unicode standard for Indic languages is derived
from ISCII. Again, ISCII is purely concerned with text encoding, not text
display. Hence MGS and SGS are not in conflict with either ISCII or Unicode.
Instead they try to solve a problem left unsolved hitherto by text encoding
schemes.
-
Do you have a set of proposed rules to
define the MGS?
The following problems are encountered
while trying to formulate a standard Glyph Set for Bangla.
-
There is not enough space to justify
a distinct glyph for every compound character. The ISO compliant font has
exactly 190 spaces available for glyphs. Out of this, 38-40 can be used
for punctuation characters, special characters and numeric characters.
This leaves us with about 150 spaces to fit the font into.
-
Compound characters may be displayed
by using two or more distinct "reduced" forms of elementary characters.
But there is no generally accepted forms for all these characters, and
font foundries differ widely in their preferences. For instance one font
may have a single glyph for "bdha", while another may use two glyphs to
display the same. Even elementary characters may be displayed as combinations
of two glyphs. For example in ItxBeng, "ka" and "pha" are combinations
of two glyphs.
-
The "elementary" set of glyphs contains
many "reduced" forms which appear in the text only in combinations. An
example is the "ra phalaa". Depending on the character the "ra-phalaa"
is applied to, its position and shape may differ. Hence some fonts use
several different glyphs for the "ra-phalaa". The standard font map must
somehow justify their number, shapes and positions. There is no literature
to guide us in this exercise.
To some extent the space restriction
actually helps us to zero in on a unique determination of the MGS. Severe
contraints must be applied on the glyph set for it to fit within the 150
allowed spaces. A lot of ambiguity is removed if we adopt general conventions
for reducing the glyph number and adhere to those conventions in all cases.
Following is a summary of basic principles that we advocate using in the
determination of the MGS.
-
Maximize Kerning: There is no need for
multiple instances of a glyph simply because the glyph must be displaced
horizontally by different amounts in different compound characters. The
correct solution is to kern whenever kerning can solve the problem.(The
font can allow you to shift a pair of glyphs horizontally, toward or away
from each other, when they occur next to each other in a text. This is
called kerning). This principle can reduce the over-usage of spaces for
"ra-phalaa" and "u-kaar" for instance.
-
Minimize Special Ligatures: Some compound
characters and special characters like "~ncha" or "shu" are so radically
distinct in shape that a space must be devoted to them. However "nda" can
be displayed as a combination of a "reduced" "na" and a "reduced" "da".
Whenever a reusable set of "reduced" elementary characters can reasonably
resolve a compound glyph, dispense with assigning a space for that compound
glyph. Which compound characters are really special and which are not is
still a subjective question. In case of doubt, MGS will settle the question
by voting for the combination display. Spaces saved in this manner can
always be re-used for the same special glyphs in the private usage area.
-
Retain one space for each elementary
character: The elementary character "aa" will be regarded by most people
as a compound glyph formed from the glyphs of "a" and "aa-kaar". MGS will
define a kerning suitable for this purpose, and MGS compliant software
should use this compound form of the glyph. Nevertheless, in the font character
map a space will be left blank following "a" to house a special rendition
of "aa". This blank space is to be regarded as belonging to the private
usage space. Similarly "ai" can be formed from "e" and a special glyph
(a "shNuR"). The "shNuR" is a desirable glyph in the MGS since it can be
re-used for "au". The MGS solution is to keep a blank space for "ai" and
"au" and put them in the private usage area. A space must be allotted to
the "shNuR" somewhere. The basic idea is that elementary glyphs must have
their own spaces arranged alphabetically in the font set. If some of them
are clearly compund glyphs and spaces can be gained by displaying them
as compounds, we will retain blank spaces for them and count these spaces
as part of the private usage area. This will allow an MGS compatible font
to be used as a character code for encoding text as in ISCII.
-
Order alphabetically: The glyph set is
to be ordered alphabetically. Special characters are to come last and will
be arranged alphabetically according to the first character they are used
in making.
-
Retain Punctuations: As mentioned before,
common punctuation marks as appearing in the ASCII charset are to be retained
in their usual positions. This will make the use of these fonts in applications
supporting a single language or font possible.
Careful consideration must still be given
to individual cases, because the above basic principles may not be enough
to resolve all issues. A sample for the MGS is proposed below with arguments
for deciding ambiguous cases. This proposal should be regarded as just
a starting point. Comments and counter-proposals are invited. It is hoped
that a workable version of MGS will emerge in a short time from these discussions.
10. Which softwares support MGS?
The members of Bangla Ring will be
committed to use the standards adopted in this forum and use them in their
computer applications. Applications developed or commisioned by them will
support these standards. Whenever a Web page needs a downloadable shared
font, an MGS compliant font will be used. Parabaas is making a multilingual
Word Processor freely available. Parabaas Axar will serve both Web and
Print publications. It is fully MGS compliant.
11. How do I make a suggestion for
the MGS/SGS?
Bangla Ring is an open public forum
to discuss issues relating to the MGS and SGS and to facilitate the evolution
of the standard. All comments, suggestions, questions should be mailed
to the WebMaster. These will be postedon this page. All issues are to be
resolved in the open moderated discussion section of Bangla Ring.
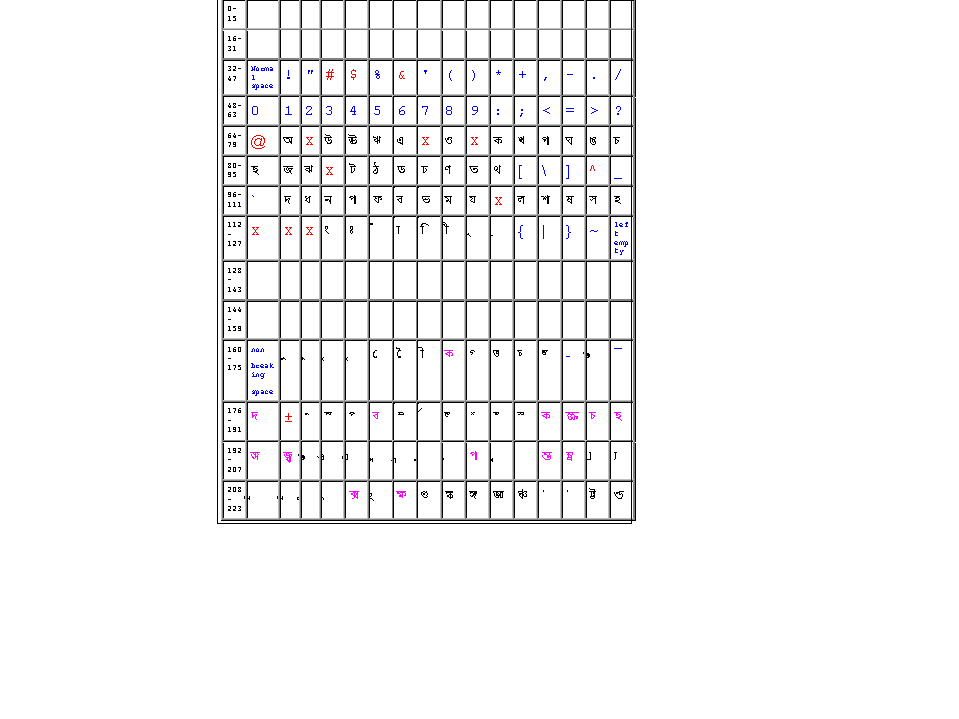
The Sample MGS
(We will
update this section as changes are suggested and made.)
Annotation:
Empty Spaces must be empty for ISO-8859
compliance. However some amount of ISO-8859 violation may still work with
todays browsers. Although there will be problems with Java.
-
Spaces with blue text match Latin 1 characters.
-
Spaces with Red Cross (X)
belong to private use area.
-
Spaces with Red text other than a Cross
also belong to private use area, but are filled with suggestions. These
may be considered last for private usage.
-
Spaces with magenta text actually denote
"reduced" suffixes or prefixes which I couldnt find in the font I used.
So I have used compound glyphs that have these suffixes or prefixes. The
only exception is r which should be a special
glyph with no "shNuR". This glyph can then be used to form both þ
and r.
-
Here is a detailed account of the logic
behind the construction:
-
0-64: Up until char 64, the Latin 1 charset
is followed, with some characters colored red these are characters that
may not be vitally important to the Bangla font set. The numerals will
of course be in Bangla. This section of the charset is simple to understand
and agree to (one hopes).
-
65-117: "aa", "ai", "au", "~na", "ra",
".Da", ".Dha" and "Ya" are absent from the MGS. These should be defined
by proper kerning of a pair of other glyphs. (For example "ai" comes by
kerning in char 235 with "e" and ".Da" and "ra" come from "Da" and "ba"
by kerning in char 237 and char 236 respectively. "Ya" (or "fa") comes
by kerning in char 236 with "ya"). However there is an empty space for
each one of the missing characters. Also, some special characters from
the ASCII set have been left alone. This section is also simple to understand
and we should have a quick agreement one way or another about the absent
characters and the special characters from ASCII (which are in blue).
-
118-167: Apart from the 32 space gap,
this interval houses the matras. Need two matras for "u", "U" and "R^i"
because they may be applied to characters extending down to the baseline
or beyond the baseline. Vertical displacement of this sort can not be handled
by kerning. There are two issues in this section: a) How many "u"s,
"U"s or "R^i"s? We have chosen the minimum (2). b) How many "e"s and "ai"s.
We have chosen 1 each, preferring to make the other forms (with matra on
top) by kerning in char 175 (which can be the top matra in this charset).
-
168-186: The reduced characters that
serve as prefixes. This and the next section are the only ones that
need very careful handling. I had identified the following characters
as needing a prefix form: ka, ga, ~Na, cha, chha, ja, ta, da, na, pa, ma,
la, sha, shha, sa. kha, gha, chha, jha, ~na, Tha, Dha, Na, pha, bha dont
seem to have any ligatures other than a "ra-phalaa" or a "ba-phalaa" which
can be applied to the un-reduced character itself. How to write "kophtaa"?
AdarshaLipi does not have a prefix for "pha" and also does not have a special
glyph for "phta". So I think we can write it with the ordinary "pha". But
I may be wrong. Ta and Da have "TTa" and "DDa" which I treated as special.
"ha" has "hla" which is usually formed using the un-reduced "ha" (but I
need confirmation of this). Initially I had intended to keep 2 forms each
for "ga", "na", "pa", "ma", "la", "sha" because they all come with a "dNaRi"
in the rear and in ligatures may either shed the "dNaRi" or keep it (think
of "shcha" and "shma" or "pTa" and "pla"). In the end I retained 2 forms
for only "na". We can probably use the un-reduced "pa" for "pla". Am
I missing a needed prefix? Maybe I should include more here just to be
safe. Which ones are best candicates?
-
187-213: Reduced characters that serve
as suffixes. This is the other hard section. kha, ga, gha, ~Na,
Ta, Tha, Da, Dha, pha, sha, shha, dont seem to have special suffix forms.
"~na" does occur in "yaach~naa", but ordinary "na" can be used for that
purpose. "tta", "tra", "bhra" and "kra" all appear as suffixes too. There
are two forms each for "na", "ra", "la" and "ba" which seem to occur very
frequently as suffixes under all sorts of characters. Is this completely
justified? (The small and nearly invisible characters in positions
208-212 are two "ra"s and two "la"s). Am I missing a needed suffix?
-
214-238: Special characters. Chars 220
and 221 appear as single quotes in the HTML this is probably due to non
ISO compatibility of AdarshaLipi. They should be "~ncha" and "~nja". The
last two dots are the dots for "ra" (and "Ya") and ".Da" (and ".Dha").
The
one that seems to be in doubt is "DDa". And the position of the last 8
glyphs can be changed so that they come before the special glyphs (i.e
start at char 214).